萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
一记漂亮的长传,直接助攻射门:

带球连过两人:

这样高超的线上足球技巧,并非上手两三年的“老玩家”做出的,而是仅仅练习了一个月的腾讯AI“绝悟”。
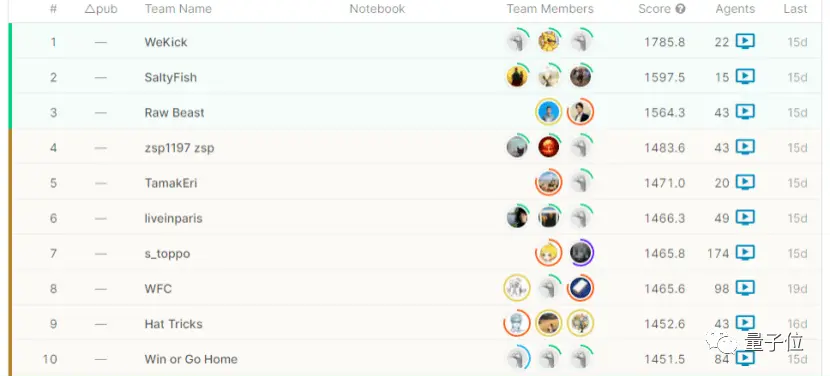
现在,战胜大部分荣耀玩家后,AI“绝悟”又化名WeKick,去试手了一把谷歌举办的线上世界足球赛。
没想到,轻轻松松就拿了个冠军回来:
嗯?打完王者,还能踢FIFA?
没错,利用迁移学习,就能让“足球版绝悟”WeKick,快速掌握踢足球的技巧。
但要想踢出多种策略、稳定掌握这些策略,还得采用不同的方法。
各种风格小模型,共同训练主模型
从“绝悟”完全体迁移过来的WeKick,针对这场足球比赛,进行了策略性的调整。
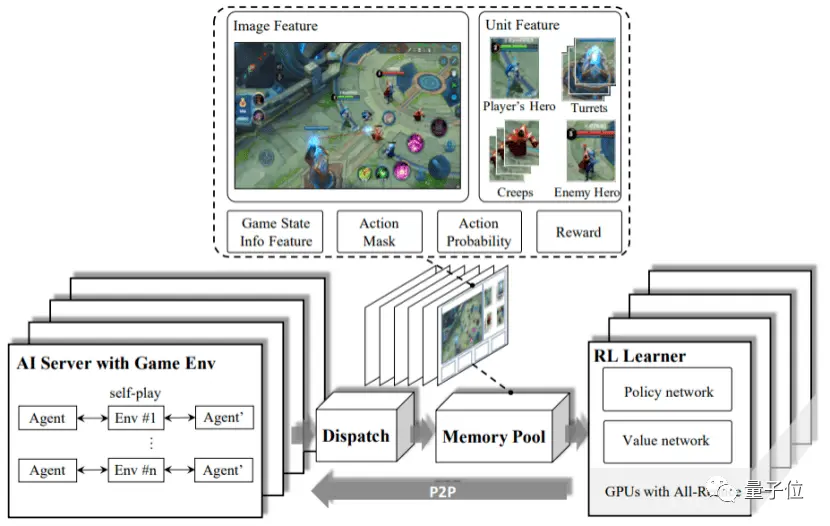
与常规足球游戏的“控制整只球队”不同,这场足球比赛中,每个队伍需要控制其中1个智能体,与游戏中的10个内置智能体组成球队(11vs11赛制)。
也就是说,每个智能体“球员”,都需要学习如何在队友之间传球,并克服对手的防守以进球。
然而采用强化学习,从0开始训练一个会踢球的AI,相当困难。
在王者荣耀等MOBA游戏中,智能体可以学习的信号非常多,包括实时经济、血量、经验等。
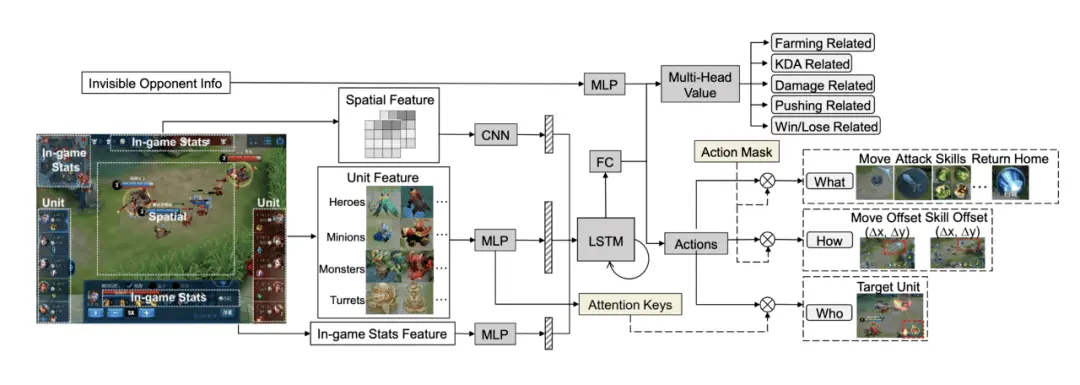
但足球游戏的激励非常稀疏,几乎只有“进球”这一项奖励机制。
稀疏激励,正是强化学习的难题之一。
为了突破这一难关,“绝悟”WeKick版本采用了3点创新,来对模型进行训练。
首先,是自博弈(Self-Play)强化学习。
WeKick部署了一种异步分布式强化学习框架,虽然会牺牲训练时的部分实时性能,但能够提升其灵活性,支持在训练过程中按需调整计算资源。
此外,WeKick还结合生成对抗模拟学习(GAIL)与人工设计奖励,采用了生成对抗训练机制。

这种机制能够模拟专家行为的状态和动作分布,使得WeKick能够从其他球队中学习经验。
之后,将GAIL训练的模型作为固定对手,再一次进行自博弈训练,就能提升策略的稳健性。
这种方法虽然不错,却存在一个缺陷。
训练后,模型容易收敛成单一风格,容易发生因“没见过某种打法”而表现失常、导致成绩不佳的情况。
因此,WeKick的团队想出了一种方法:采用多风格强化学习的训练方案,让智能体“球员”们先专精一个领域,再进行配合。

也就是说,先训练一群具备一定竞技能力的基础模型,每个模型分别掌握运球过人、传球配合、射门得分……
然后,基于基础模型,训练出多种风格的各个模型,过程中会定期加入主模型作为选手,避免模型坚持原来的风格。
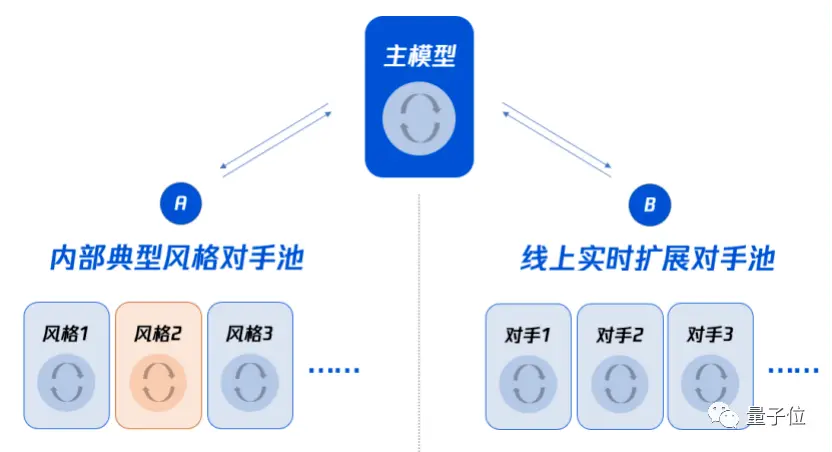
最后,将这些模型集合起来,训练一个主模型,期间除了主模型以历史模型为对手,还会拿所有风格化基础模型当对手,确保主模型能应对各种风格的踢球方式。
通过这3种方式训练出来的模型WeKick,既具有丰富的足球经验,也能准确地对抗各种不同风格的比赛技巧。